XGBoost를 이해하기 위해서는 (1) 앙상블 학습 기법과 (2) Gradient Boosting에 대한 이해가 선행되어야 한다.
앙상블 학습 기법이란?
여러 개의 약한 학습기(Weak Learner)를 결합하여 강력한 학습기(Strong Learner)를 구성하는 방법을 의미하며, 크게 bagging과 boosting으로 나뉜다.
Bagging(Bootstrap Aggregating) 이란?
여러 개의 학습 데이터셋을 '랜덤하게 복원 추출'하여 '각각의 데이터 세트에 대해 독립적으로 약한 학습기를 학습시키는 방식'으로, 복원 추출을 허용하므로 중복된 데이터를 학습하는 경우가 포함되기도 한다. 그리고 이렇게 학습된 약한 학습기들의 예측 결과를 평균 또는 다수결 등 방법으로 결합하여 최종 예측을 수행한다. 약한 학습기들이 독립적으로 학습되고 예측되므로 '병렬적'으로 처리할 수 있으며, 대표적으로 'Random Forest' 알고리즘이 있다.
Boosting 이란?
약한 학습기들을 '순차적으로 학습시켜 가중치를 부여'하여 강력한 학습기를 만드는 방법이다. 초기에는 전체 학습 데이터 세트를 사용하여 약한 학습기를 학습시키고, 이후에는 이전 학습기가 잘못 예측한 샘플에 가중치를 부여하여 다음 학습기를 학습시킨다. 이처럼 학습과 가중치 업데이트를 반복적으로 진행하면서 약한 학습기들이 순차적으로 강화되어 최종 예측기를 형성한다.
정리하자면,
약한 학습기를 강한 학습기로 구성하는 방법을 앙상블 학습 기법이라고 하며, 앙상블에는 Bagging과 Boosting 방식이 있는데 두 방식은 약한 학습기를 강한 학습기로 만드는 방식에 차이가 있다.
- Bagging은 병렬적인 학습과 복원 추출을 통해 약한 학습기를 결합하며,
- Boosting은 순차적인 학습과 가중치 업데이트를 통해 약한 학습기를 강화시키는 방법이다.
** 약한 학습기(weak learner)
- 일반적으로 성능이 중간 정도인 간단한 모델
- 단독으로는 예측 성능이 좋지 않지만, 여러 개를 결합하여 강력한 모델 형성 가능
- 예를 들어, 의사결정나무 한개의 얕은 트리가 약한 학습기가 될 수 있음
** 강한 학습기
- 더 복잡하거나 성능이 우수한 모델
- 일반적으로 약한 학습기보다 더 많은 계산 또는 리소스를 요구할 수 있음
- 예를 들어, 랜덤 포레스트의 많은 의사결정나무가 강한 학습기가 된다.
Gradient Boosting 이란?
Gradient(잔차, residual)를 이용하여 이전 모형의 약점을 보완하는 새로운 모형을 순차적으로 fitting한 뒤, 이를 선형 결합하여 얻어진 모형을 생성하는 Boosting 알고리즘의 일종으로 조금 더 발전된 방법이라고 볼 수 있다.
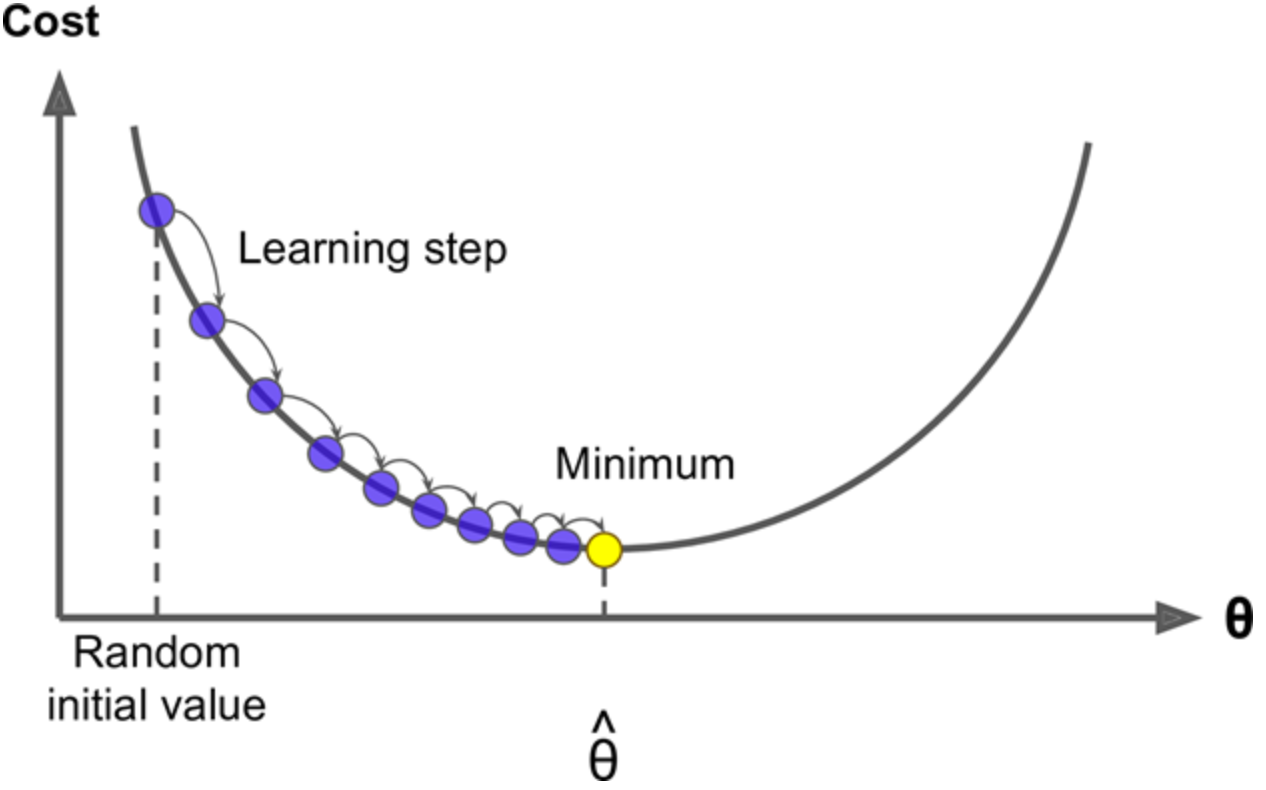
Boosting 알고리즘의 일종이므로 이전 학습기의 오차(residual)를 최소화하는 방향으로 새로운 학습기를 추가해 나가게 되며, 경사하강법(Gradient Descent)을 활용하는 부스팅 방법이라고 볼 수 있다.
GB는 기존의 estimator를 수정해나가는 방식을 채택하지 않고, 매 단계마다 아예 새로운 estimator를 생성하며, 이 과정에서 경사하강법을 사용하여 모델의 오차를 줄여 나간다.
만약, 2가지 조건(성별, 키)와 몸무게를 y로 하는 데이터가 있고 비용 함수를 MSE로 했을 때의 모델의 학습 과정은?
(1) 1차 추정기(estimator)는 성별을 기준으로 삼는다.
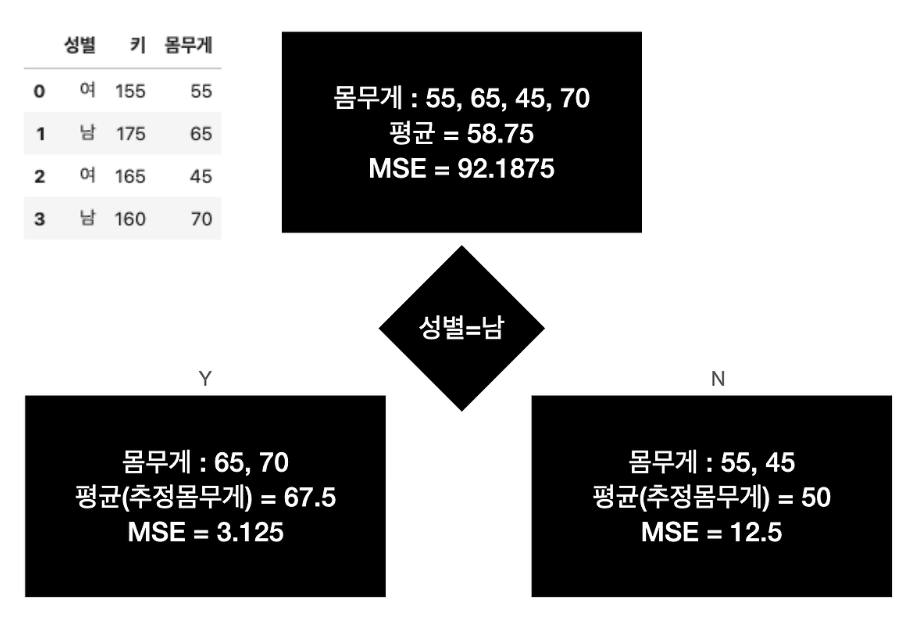
- 이에 따라 두 자식 노드가 생겨나고, 각각 평균값이 예측값(추정 몸무게)이 되고, 각각의 MSE도 계산된다.
(2) 2차 추정기(estimator)는 잔차(residuals)를 입력값으로 삼는다.

- 이전 학습기가 잘못 예측한 샘플에 가중치를 부여하여 학습하는 부스팅의 아이디어를 토대로, GB에서는 잔차를 입력값으로 하여 아이디어를 실행한다.
- 다음으로 2차 추정기는 키 160을 기준으로 삼아, 두 자식 노드가 생겨나고 노드에 속한 값들의 평균이 2번 추정기의 추정 몸무게가 된다.
(3) 최종 estimation :: 1차 추정기의 예측값과 2차 추정기의 예측값을 더하면 최종 예측값이 된다.
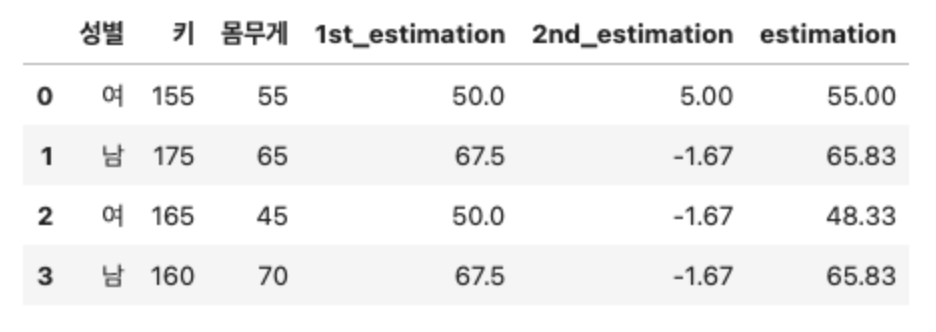
위의 추정 과정을 반복하고, 그 과정에서 생성되는 MSE를 경사하강법으로 학습하는 것이 XGBoost의 모델 학습 과정이다!
추정(estimation)
모집단으로부터 추출된 표본으로부터 모수의 값을 추측하는 통계적 절차
추정량(estimator)
모수를 추정하기 위한 관찰가능한 표본의 함수
추정값(estimate)
추정량이라는 함수에 실제 관찰치를 대입하여 계산한 추정량의 값
그렇다면, GBM(Gradient Boosting)과 XGBoot는 뭐가 다를까?
- GBM과는 달리 XGBoost는 병렬 학습이 지원되도록 구현된 라이브러리라는 점이 다르다. (성능과 자원 효율 측면에서 우수함)
- 이외에도,
- XGBoost는 GBM에 비해 Overfitting이 더 잘 발생하기 때문에 정규화(regularization)에 더 신경써야 함
- GBM에 비해 XGBoost는 목적과 평가기준에 맞는 설정이 가능하기 때문에 Highly Flexible하지만, 그만큼 하이퍼파라미터 설정의 난이도가 높음
- .... 등이 있다.
https://yamalab.tistory.com/215
XGBoost 알고리즘의 간단한 이해
캐글에서 가장 유명한 알고리즘은 XGBoost이다. 웬만한 대회의 리더보드에는 XGBoost가 최상단에 위치해 있다. 이가 시사하는 바는, Vision 이나 NLP 등의 Specific한 Task를 제외한 일반적인 ML Task에서 가
yamalab.tistory.com
Boosting 알고리즘 - XGBoost 특징 및 장단점
이번 포스팅에서는 부스팅 알고리즘 시리즈 중에 강력하다고 손꼽는 XGBoost 알고리즘에 대해 살펴보겠습니다. Light GBM(LGBM)이 나오기 전에는 XGBoost 만큼 성능 좋은 알고리즘이 찾기 힘들 정도였죠
bommbom.tistory.com
https://m.blog.naver.com/soohwan2-/100200023641
추정(estimation) vs 추정량(estimator) vs 추정값(estimate)
이어서~ 추정량, 추정값, 추정에 대해 알아보도록 하겠습니다. 다 비슷비슷해서... 자주 헷갈리시죠...
blog.naver.com
'기초지식' 카테고리의 다른 글
| Logistic Regression (0) | 2024.05.09 |
|---|---|
| SVM(Support Vector Machine) (0) | 2024.05.09 |
| Hyperparameter Optimization (0) | 2024.05.09 |
| Random Forest (0) | 2024.05.08 |
| Data Scaling (0) | 2024.05.08 |



