Computer vision 분야에서는 '컴퓨터가 이미지를 어떻게 읽는지'를 먼저 이해해야 한다.
MNIST 데이터셋을 이용하여, 컴퓨터가 이미지를 읽어들이는 방식을 이해하기
- 인간은 손글씨 그림을 이미지로 잘 인식하지만, 컴퓨터는 각각 픽셀의 값을 숫자로 인식한다.
- 가장 밝은 부분은 255, 아무 value가 없는 부분은 0
CIFAR 데이터셋을 이용하여, 컴퓨터가 이미지를 읽어들이는 방식을 이해하기
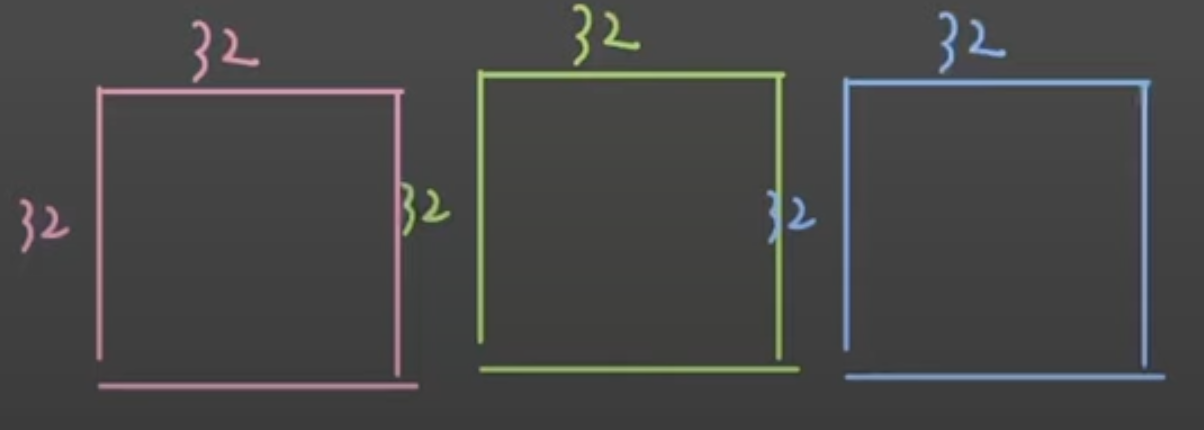
- 컬러 이미지의 .shape을 출력해보면 (32, 32, 3)이다.
- 가로가 32 픽셀, 세로가 32 픽셀이고 컬러이기 때문에 RGB 총 3개의 채널을 가진다는 것을 의미
- 그렇게 되면 Neural Network의 input_size는 32 x 32 x 3 = 3072가 되는데, 이게 이미지 벡터의 크기이다.
이미지 데이터를 Neural Network에 넣어주기 전에 거쳐야 하는 추가적인 작업들이 있다.
- input size가 정해져 있기 때문에 NN가 이해할 수 있는 인풋 이미지 사이즈로 resize 해주어야 한다.
- unstand integer 8의 데이터 형식을 가지는 각 픽셀 값들을 float 데이터 형식으로 바꿔 주어야 한다.
- 0~255 사이의 값을 가지는 데이터들을 일반적으로 0~1 또는 -1 ~ +1 사이를 갖도록 normalization 해주어야 한다.
- 파이토치나 텐서플로우가 이해할 수 있는 데이터 타입 텐서 형태로 바꿔준다.
- 이미지 타입 같은 경우, dimension의 순서를 바꿔 주어야 한다.
- (32, 32, 3)에서 이미지 depth의 경우 가장 마지막에 오지만, 파이토치의 경우 depth를 가장 먼저, 그리고 높이(H), 너비(W)의 순서를 갖도록 해야 한다.
- NN을 배치 학습으로 트레이닝 시켜야 하므로, 배치 작업을 적용한다.
- 그러면, 트레이닝을 한번 시킬 때마다 뉴럴 네트워크로 들어오는 input dimension은 float 형식의 normalize된 해당 텐서가 된다.
유튜브 강의 및 코드
https://www.youtube.com/watch?v=6MWlrSNXYi8&list=PLDV-cCQnUlIaIFHQwuXRRSL833cRAS76M&index=1
'Deep Learning & Machine Learning > Computer Vision' 카테고리의 다른 글
| [코드없는 프로그래밍] 딥러닝, CNN options (0) | 2024.04.15 |
|---|---|
| [코드없는 프로그래밍] 딥러닝, CNN Depth Channel (0) | 2024.04.15 |
| [코드없는 프로그래밍] 딥러닝 CNN (0) | 2024.04.15 |
| [코드없는 프로그래밍] 딥러닝 이미지 전처리 (0) | 2024.04.14 |
| 컴퓨터 비전 개요 (0) | 2024.04.13 |

